The Architecture Story
What you actually have vs. what you think you have. We map the real system topology and compare it to stated architecture. Every gap is a risk you didn't know about.
We read the decision history your systems left behind — code, commits, tickets, ownership — and turn it into answers your board can act on. Delivered in three weeks, then kept current as your systems change.
Every system is a dig site. The code is one layer. The commits, the tickets, the PRDs, the deployment history, the team structure — each one preserves decisions nobody remembers making. We excavate all of them.
We don't audit code quality. We answer business questions.
We get read-only access to your systems. No disruption to your team.
Our tooling correlates everything. Commits to tickets. Tickets to requirements. Requirements to code. We build the real picture.
You get answers you can act on. Stories backed by data, options backed by numbers.
Our tooling surfaces everything hiding in your system — across code, commits, tickets, PRDs, and deployment history. Our practitioners turn those findings into decisions you can act on.
Which risks are actively slowing you down, which are safely dormant, and what each one means for the business. Not "high complexity" — actual implications.
SOC 2, PCI DSS, GDPR, NIST — readiness scored per framework. Gaps identified with remediation priority.
Where you're exposed — security holes, leaked secrets, end-of-life dependencies and license traps — framed as the risk an acquirer or regulator would flag, not a raw CVE list.
Fix, rebuild, or hybrid — each option with effort, timeline, and risk reduction. An independent read you can act on, not a rebuild we're selling.
GitHub, GitLab, or Bitbucket. We clone and analyze. We never write.
Read-onlyJira, Linear, or equivalent. We map tickets to commits to understand intent.
Read-onlyPRDs, architecture docs, runbooks. Whatever exists. Sparse is fine.
Read-only30 minutes. We ask the questions your team won't ask each other.
30 minHow a question becomes an answer
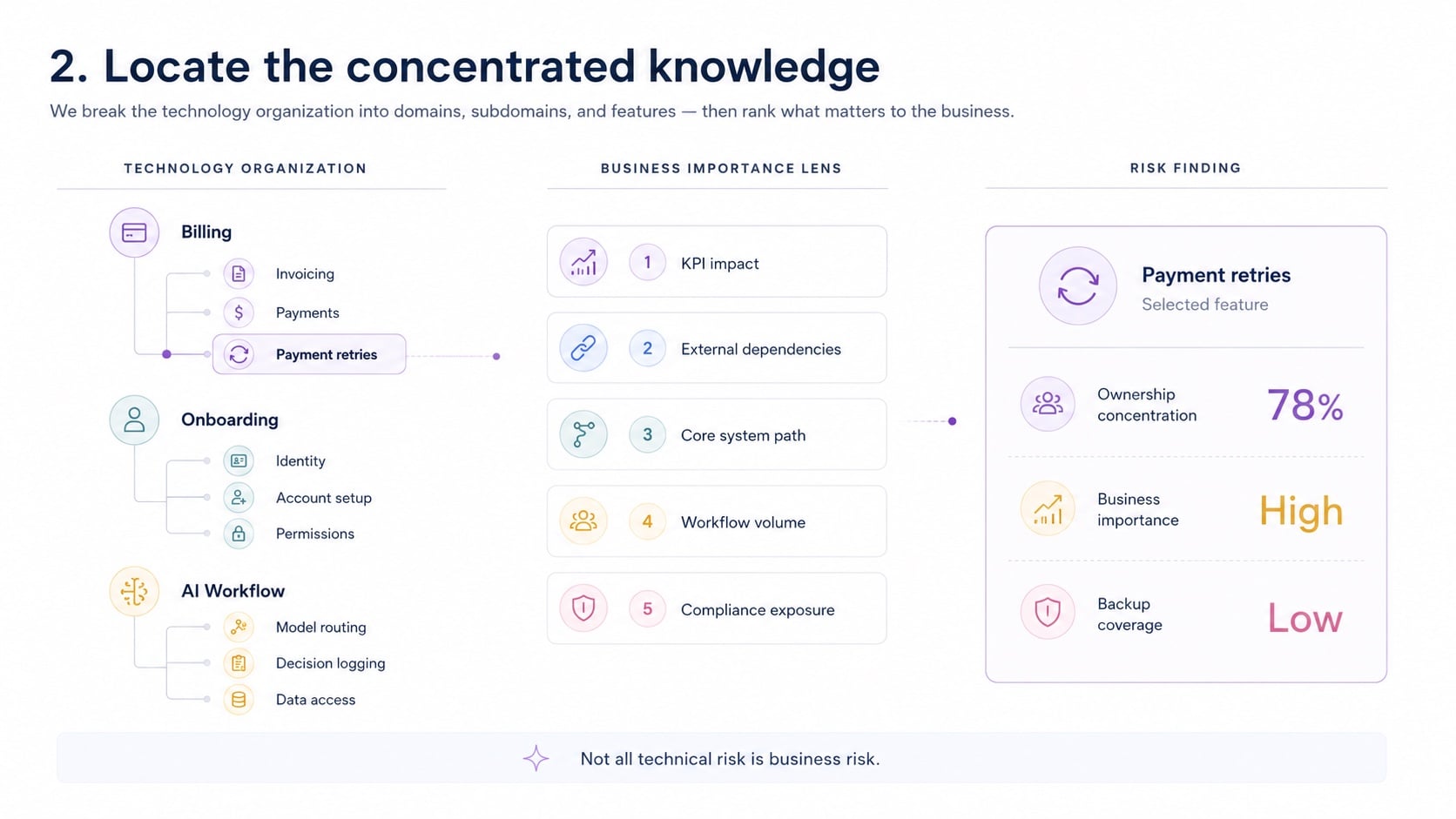
We start with the question a leader actually has, break it into sub-questions, name the exact records that answer each, and pull them. Here is one question, end to end.
“What breaks if a key engineer leaves?”
↳ git authorship + merge/blame history
↳ single-author analysis across the commit graph
↳ dependency & call graph
↳ tickets, PRDs, comments, doc coverage
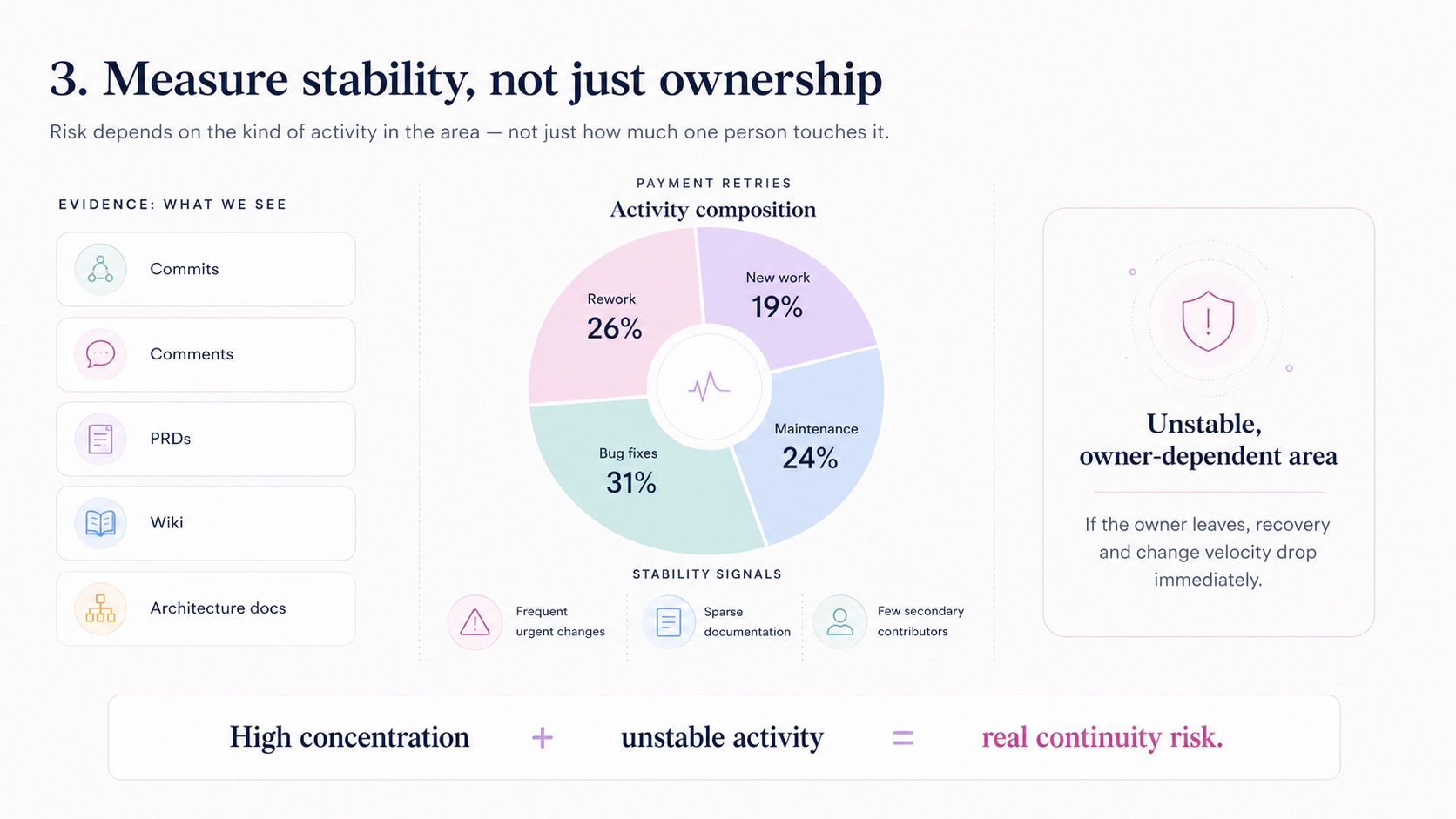
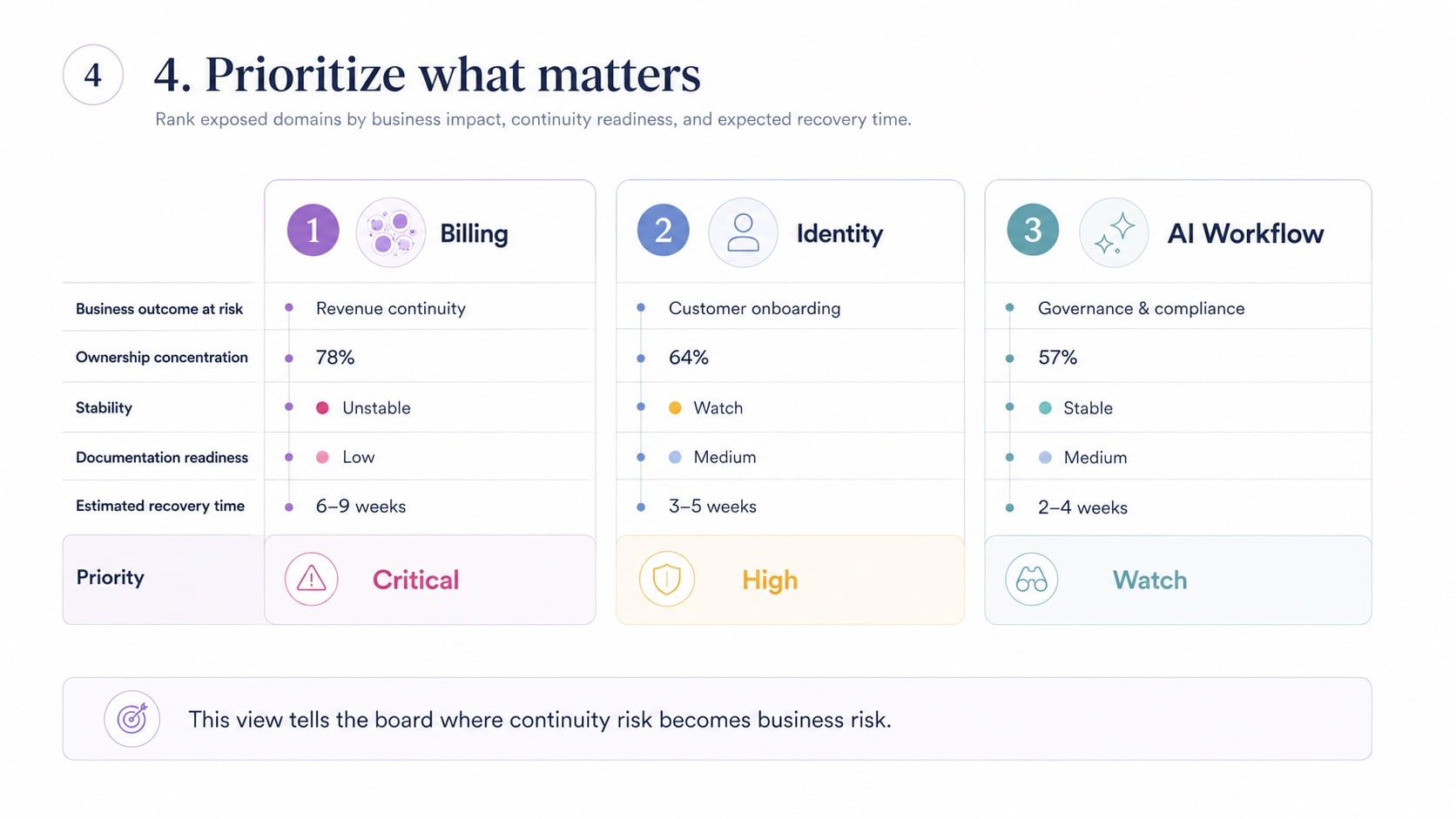
Bus factor = 1 across every top-10 component (95% confidence). One person authors 100% of PROD / PROD-FIX / UAT merges and solely owns a 1,496-node Authentication module — roughly $9,000 of manual triage per change (100% confidence). Modeled retention exposure: $600K–$1.2M (modeling assumption).
The read, step by step
The same question, walked through the read — from the business outcome at risk to a 30/60/90-day plan. Click a step, or use the arrows.


Why this is doable — the mapping
Making it mean something — grouping it into areas, seeing how they depend on each other and which ones carry the weight, in one repo, across a project, and up the whole stack — is the read.
Files and functions roll up into modules, modules into business domains. We resolve who owns each area and what is coupled to what.
A 1,496-node Authentication module — single-author, with 1,332 nodes reflection-bound, so its blast radius can’t be traced statically. (100% confidence)
Many repositories make one product. We follow the shared contracts between them, so a change in one place shows its real reach.
One intake DTO fans into 7 projects — a single change forces a platform-wide rebuild. (no feature flags; rollback = redeploy)
Beyond your code: the vendors, models, and external systems the product leans on — each mapped to where it creates risk.
23 vendor integrations with no shared abstraction, plus 8 bureau-scoring decisioning systems. (consequential-decision AI surface)
How the read is built
Three layers, each checked by our experts. We start with deterministic scanners — not AI — so every finding is grounded in your actual code. That precision is what protects the read from AI hallucination.

Layer 1
Precision scanning
Deterministic static analysis, not AI. It reads your code exactly as written, so every finding traces to a real line, commit, or file. Nothing is inferred.
Layer 2
Semantic mapping
The mapping shown above — scanned facts correlated across commits, ownership and history, then grouped into your business domains by relationship and importance. Checked by our practitioners, never left to an AI’s guess.
Layer 3
Knowledge base
The correlated read becomes a queryable layer your team keeps — the same grounded evidence, live, for the next question.
Five narratives backed by evidence, compliance scorecards, strategic options, and a searchable knowledge base of your entire system.
What you actually have vs. what you think you have. We map the real system topology and compare it to stated architecture. Every gap is a risk you didn't know about.
Who knows what, and what happens when they leave. We identify knowledge concentration, single points of failure in your team, and the institutional memory that lives only in someone's head.
Where technical debt concentrates and what it costs. Not every debt matters. We show you which debt is actively slowing you down and which is safely dormant.
Is the team building what the roadmap says — or spending cycles on maintenance, gap-closing, and work nobody decided to prioritize? We show you where engineering time actually goes vs. where the business thinks it goes.
Is investment following the strategic plan — or going to maintenance, rework, and decisions nobody made? We show where the money actually goes vs. where the business thinks it goes.
Code audits tell you what's wrong with your code. We tell you what your code means for your business. We answer questions about risk, knowledge, cost, and velocity — not code formatting.
One 30-minute call with a stakeholder. That's it. We work from the code, not from interviews. People forget. Code doesn't.
Most documentation is. That's actually useful data — the gap between what's documented and what exists tells its own story. Our tooling works from the code first.
Read-only access, always. We never write to your systems. Data is encrypted in transit and at rest. We can work within your VPN. SOC 2 compliant.
Fixed-price engagement scoped to your codebase. The quote depends on the number of repositories and the complexity of the system. You get a firm number before we start, and the price doesn't change.
Three weeks from access. Week one is connect, week two is mapping, week three is analysis and delivery. The executive briefing happens at the end of week three.
Fixed-price, scoped to your codebase. The quote depends on the number of repositories and the complexity of the system. You get a firm number before we start, and the price doesn't change.
No retainers. No ongoing subscriptions. One engagement, one deliverable. If you want quarterly pulse updates afterward, that's a separate conversation.
What you receive stays with you. The knowledge base we build becomes the foundation for everything that comes next — safer AI adoption, faster onboarding, decisions that don't require asking the team that built it.
We read every signal the system emits — the code, the commit history, the tickets, the PRDs, the roadmaps, ownership, tests and data — and correlate them over time rather than at a single snapshot. Deterministic static analysis surfaces what's there; multi-source temporal correlation ties it together; and every finding is mapped to your business domains and features, not the repository tree. A pattern in any one source is noise. A pattern across all of them, over time, is a finding. The output isn't a scan score — it's a defensible read of what's true about the system and why it became that way.
A scanner tells you what the code is — the violations, the complexity, the dependencies. It can't tell you why it was built that way, which is where the risk and the decisions actually live. A module looks over-engineered until you learn it was built for a contract that no longer exists; a service looks fragile until you find the one person who has quietly kept it alive. We call the discipline decision archaeology: reconstructing the sequence of decisions that shaped the system — including the ones nobody wrote down — so you can act on cause, not just symptom.
Interviews give you what people remember and what they're willing to say. The system itself can't forget, can't spin, and has no stake in the answer. So we let it testify: the commit that introduced the workaround, the ticket that was closed without a fix, the dependency that hasn't been updated in three years. Where the team's account and the evidence disagree, the evidence wins — and that's precisely what makes the read defensible to a board, an acquirer, or a regulator.
A scanner hands you a thousand warnings and a score; a dashboard hands you metrics with no story. Both leave the interpretation to you. We do the opposite: technology finds the data, experience finds the truth. The deliverable is the Five Stories — architecture, knowledge, risk, velocity, investment — each one a decision you can defend, in business language, traceable to the commit. Not a tool you have to run and read yourself, but a read you can act on.
What We Are Not
We don't write code, manage your engineering team, or sell you a transformation roadmap. Our only interest is an accurate picture — which is exactly why you can trust it. What happens next is your decision, made with the right information for the first time.
Where the read applies
Technical due diligence · Code & software audit · AI compliance & shadow-AI · Private equity · M&A · New & fractional CTOs · CEOs & boards · Glossary